
Yapay Zekâda Türkçe Odaklı Yeni Bir Ölçüm: HCBfT Benchmark Veri Kümesi
Büyük dil modellerinin Türkçe anlama, sözel mantık ve kültürel nüans yeteneklerini daha etkin biçimde sınamayı amaçlayan HCBfT, bilişsel açıdan zorlu ve manipülasyona dayanıklı bir kıyaslama veri kümesi sunuyor. Bu yeni “benchmark” için oluşturduğumuz ilk sürüm olan TR200 testinde, ticari modeller arasında Google’a ait Gemini 3 Flash %68 başarı düzeyiyle lider. Açık modellerde ise Fransa çıkışlı Mistral Large en yüksek performans/fiyat oranını elde etti.
Yazar: Dr. Emre Kızılkaya, GSÜ İletişim Fakültesi Misafir Öğretim Görevlisi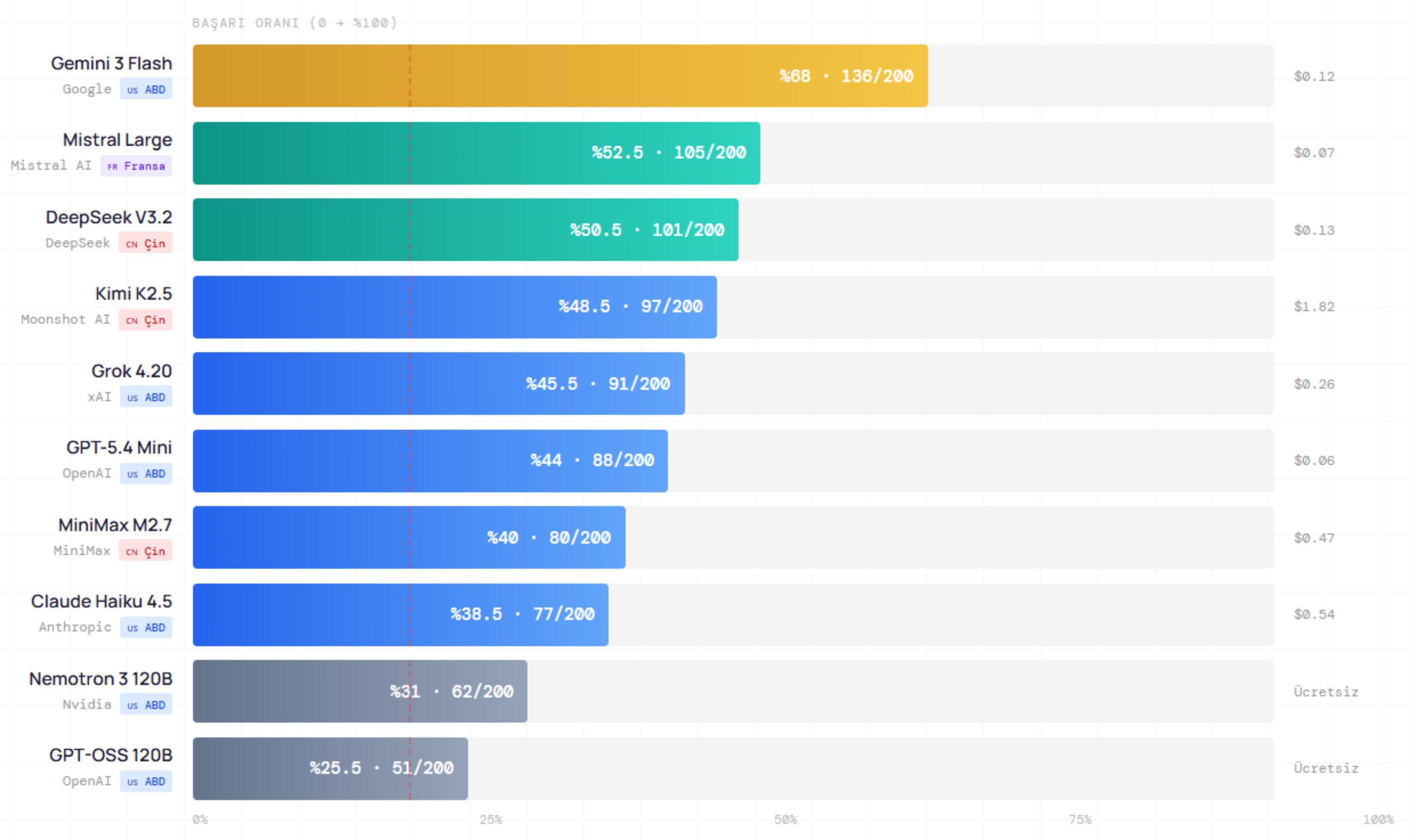
Programlama arayüzleri (API) üstünden HCBfT-TR200 ile test ettiğimiz 10 ticari modelin başarı oranları ve maliyetleri. Kırmızı kesik çizgi, 5 seçenekli sorularda şans eşiği olan %20’yi gösteriyor.
Yapay zekâ (YZ) modelleri için hazırlanan ve “benchmark” diye de bilinen birçok başarım sıralamasında, OpenAI’ın GPT, Anthopic’in Claude, Google’ın Gemini markalı büyük dil modeli (LLM) ürünleriyle %100’e giderek yaklaştığını, Çin’den çıkan modellerin performansının da hızla yükseldiğini görüyoruz.
Türkiye’deki kamu kurumlarının, şirketlerin, sivil toplum kuruluşlarının ve araştırmacıların bu ortamda sorması gereken kritik bir soru var: Bu sistemler Türkçe’yi ve Türkiye'nin kültürel kodlarını gerçekten anlıyor mu? Birçoğu ABD’de hazırlanan bu ‘benchmark’lar, modellerin Türkçe performansını da doğru ölçebiliyor mu?
YZ entegrasyonuna hazırlanan kurumlar açısından, İngilizce odaklı geliştirilen modellerin Türkçe ve Türkiye bağlamındaki performansını ölçmek, veri egemenliği ve maliyet gibi boyutlarıyla stratejik bir zorunluluk. Üstelik bu hiç kolay bir iş değil.
Türkçe, sondan eklemeli ve morfolojik açıdan zengin, iletişim kapasitesi yüksek ve matematiksel mantığa yakın bir dil Tek bir fiil kökü; zaman, kişi ve kip bilgisini birden kodlayan düzinelerce sözcük biçimi türetebiliyor. Sözdizimindeki esneklik, sayısız vurgu farkı yaratabiliyor. “Lastik gibi” olması, anlamsal zenginliğin yanı sıra, yanlış anlamalara da kapı aralayabiliyor. Temel dil modellerinin büyük çoğunluğunun eğitildiği İngilizce ise daha çözümleyici bir yapıya sahip. Türkçe kelimelerin “fişleştirilmesi” (tokenization), yani modelin metni işlemek için parçalara bölmesi daha karmaşık. İngilizce ile kıyaslandığında Türkçe’de 15 kata kadar daha fazla "fiş" tüketebiliyor. Bu da modelin bilgi-işlem maliyetini artırırken Türkçe “anlamasını” ve anlatmasını” zorlaştırıyor.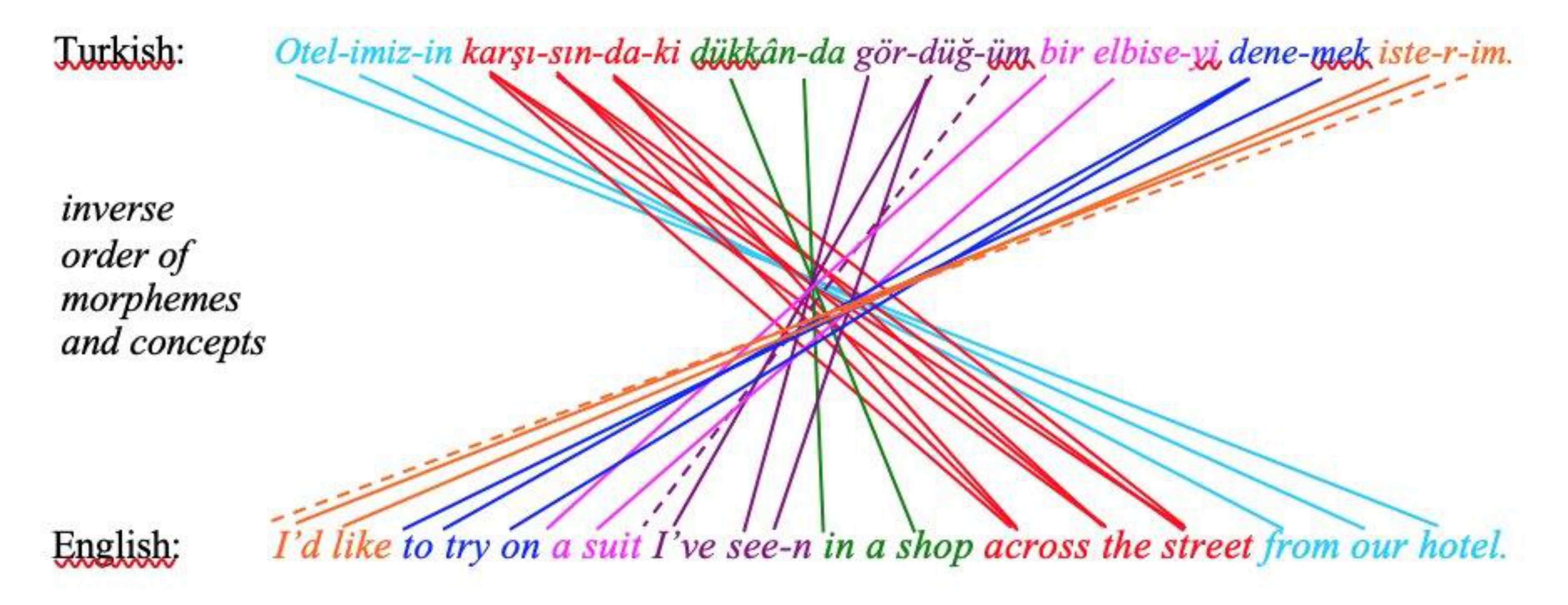
Şekil 1:
Türkçe ile İngilizce arasındaki morfemlerin ve kavramların ters sıralaması. Bu yapısal farklılık, derin anlamsal kavrayışı değerlendirmek için doğrudan çeviri süreçlerinin yetersizliğini ortaya koyuyor. Kaynak: Earls, S., Doğan, F., Darbutaite, R., & Has Bıyıklı, B. (2009). Simultaneous interpretation between languages with inverse structure. Faculté de traduction et d’interprétation de l’Université de Genève.
Vaswani ve arkadaşlarının 2017’de yayımladığı "Attention Is All You Need" başlıklı makaleden sonra, “dönüştürücü” (transformer) adı verilen sinir ağı mimarisinin doğal dil işlemede (NLP) çığır açıp ChatGPT gibi ürünleri doğurmasından bu yana geçen yıllarda, dil modellerinin Türkçe performansını değerlendirmek adına alana değerli katkılar sunan birçok çalışma hayata geçirildi. TurkishMMLU,TR-MMLU, CETVEL,Mukayese ve TurkBench gibi veri kümeleri; doğrudan çevirinin yetersizliğini kanıtlamak, Türkçe fişleştirmenin önemini vurgulamak ve kültürel öğeleri sürece dâhil etmek gibi önemli adımlar attı. Ancak bugüne kadarki çalışmaların tasarımlarında bazı kritik eksiklikler göze çarpıyor.
Mevcut veri kümelerinin neredeyse tamamı, orta ve yüksek öğretim sınav sorularına dayandığı için; gündelik yaşamı kapsayan ve profesyonel alanlarda ihtiyaç duyulan ileri düzey ve çok çeşitli bilgi ve becerileri ölçmekte yetersiz kalıyor. Dahası, bu veri kümeleri, çoğu ABD, Çin ve AB’de üretilen modellerin kalıp ezberlerini ve İngilizce mantık kurgularını açığa çıkaracak dile özgü "anlamsal tuzakları" (adversarial robustnes) yeterince barındırmıyor.
Son olarak, bu çalışmalar genellikle internette cevaplarıyla birlikte kolayca bulunup indirilebilen sınav sorularından derlendiği için, veri kümelerinin modellerin eğitim sürecine sızarak "veri kirliliğine" (data contamination) yol açma riski var. Bu durum, modellerin mevcut testlerde elde ettiği yüksek skorların, Türkçe için gerçek bir anlamsal kavrayıştan mı, yoksa sadece soruları önceden ezberlemesinden mi kaynaklandığını belirsizleştiriyor.
HCBfT Neyi, Nasıl Ölçüyor?
Daha etkin ve verimli bir ölçüm yapabilmek için, Prof. Dr. Kerem Rızvanoğlu’nun öncülüğünde, “Türkçe İçin Bilişsel-Yoğun Bir Değerlendirme Ölçütü: High-Cognitive Benchmark for Turkish” (HCBfT) adını verdiğimiz yeni bir soru kümesi hazırladık. “Medyada ve İletişimde Yapay Zekâya Giriş II (COM 148)” dersinin öğrencilerinin de katkısıyla sunduğumuz yayın öncesi makalemizde, HCBfT'nin ilk versiyonu olan TR200 veri kümesiyle ilgili ayrıntıları bulabilirsiniz. Şu sayfada ise bu ay ilkini tamamladığımız HCBfT-TR200 testinde hangi modelin kaç puan aldığını etkileşimli grafikler üstünde inceleyebilirsiniz.
Bu çalışmada özetle, daha önceki verileri tarayarak 300 binden fazla çoktan seçmeli sorudan oluşan bir başlangıç havuzunu süzüp güncel modellerin en çok zorlandığı soruları belirledik. Ardından kendi yazdığımız özgün soruları da ekleyerek, Türkiye'ye özgü mesleki alan bilgisini, karmaşık sözel mantığı, gündelik hayat pratiğine dair bilgileri, yöresel ağızları ve kültürel uyumu anadil seviyesindeki bir kavrayışla test eden en zorlu 200 soru ile veri kümesini oluşturduk.
Çalışmamızın ayırt edici özelliklerinden biri, LLM üreticilerinin olası manipülasyonlarına dayanıklı bir test oluşturma hedefimizden kaynaklanıyor. Bu bağlamda, NLP araştırmalarında “hasmane” (adversarial) diye nitelenen taktikler uyguladık. Mesela modelleri İngilizce aktarımlı akıl yürütme ezberlerinden kurtarmak için (örneğin “altı” kelimesinin hem “6” hem de “bir şeyin alt kısmı” anlamına gelmesinde görülen türden Türkçe eşseslilikten kaynaklanan) anlamsal tuzaklar tasarladık.
Bazı modellerin, “Bu sorunun cevabı A şıkkı olmalı ama Türkçe sınavlarda böyle tuzaklar kuruluyor, o yüzden B şıkkını seçiyorum” gibi yorumlarını akıl yürütme süreçlerinde gördükten sonra, bu tür “alışılmış” tuzakları da tersine çeviren yeni seçeneklerle bazı soruları tekrar yazdık. Ayrıca modellerin kalıp eşleştirme (pettern matching) zaaflarınıölçmek için bazı yanlış seçeneklerin yanına "(doğru seçenek bu)" gibi sözde cevap anahtarından arta kalmış gibi görünen yanıltıcı ifadeler eklediğimizde, test edilen 20 modelin 13'ünün bu tür bir “komut enjeksiyonu” (prompt injection) tuzağına düştüğünü gördük.
HCBfT-TR200 Puan Durumu
Geliştirdiğimiz bu veri kümesiyle 10'u uygulama programlama arayüzleri (API) üzerinden erişilebilen, 10'u ise kurumların kendi yerel donanımlarında çalıştırabileceği 20 güncel modeli test ettik. Sonuçlar, ölçek ve popülaritenin her zaman Türkçe yetkinliği anlamına gelmediğini kanıtlıyor:
- Ticari Modeller: API üzerinden erişilen ticari modeller arasında, ABD merkezli Google’a ait Gemini 3 Flash birinci olsa bile, doğruluk oranı %68’de kaldı. OpenAI, Anthropic ve X AI gibi önde gelen YZ şirketlerinin “baş altı” modellerinin %50’ye bile ulaşamaması dikkat çekici.
- Açık Ağırlıklı (Open-Weight) Modeller: Fransa merkezli Mistral AI tarafından geliştirilen Mistral Large (2512) modeli %52,5 başarı sağlarken doğru cevap başına 0,07 dolar maliyetle bütçe ve performansı dengeliyor. Çin çıkışlı modeller de hem ticari hem açık ağırlıklı tarafta üst sıraları zorluyor.
- Yerel Dağıtım (On-Premise): Yerel modeller arasında en yüksek doğruluğa %42 ile Google’ın açık ağırlıklı modeli olan Gemma 4 31B IT ulaştı. Mistral’in küçük modeli Ministral 3 14B ise gigabyte başına 6,7 doğru cevapla yerel donanımlarda en yüksek verime sahip. Veri gizliliği nedeniyle modelleri kendi sunucularında barındırmak isteyen, buna karşın tüketici sınıfı donanıma (24 GB VRAM altı) ve kısıtlı bütçeye sahip kurumlar (örneğin üniversite birimleri, KOBİ’ler vb.) için önemli bir bilgi.
- Geride Kalanlar: Her soruda beş seçenek sunulduğundan rastgele bir tahminin bile %20 doğruluğa ulaşması beklenir. Ancak bazı modeller bu sınırın dahi altında kaldı. Örneğin test ettiğimiz en küçük yerel model olan Microsoft’un Phi-4 Mini Reasoning için doğruluk oranı %11,5. OpenAI’ın açık ağırlıklı OSS modeli de, ne API üstündeki büyük (120 milyar parametre), ne de yereldeki küçük (20 milyar parametre) varyantlarıyla %30 doğruluğu aşabildi.
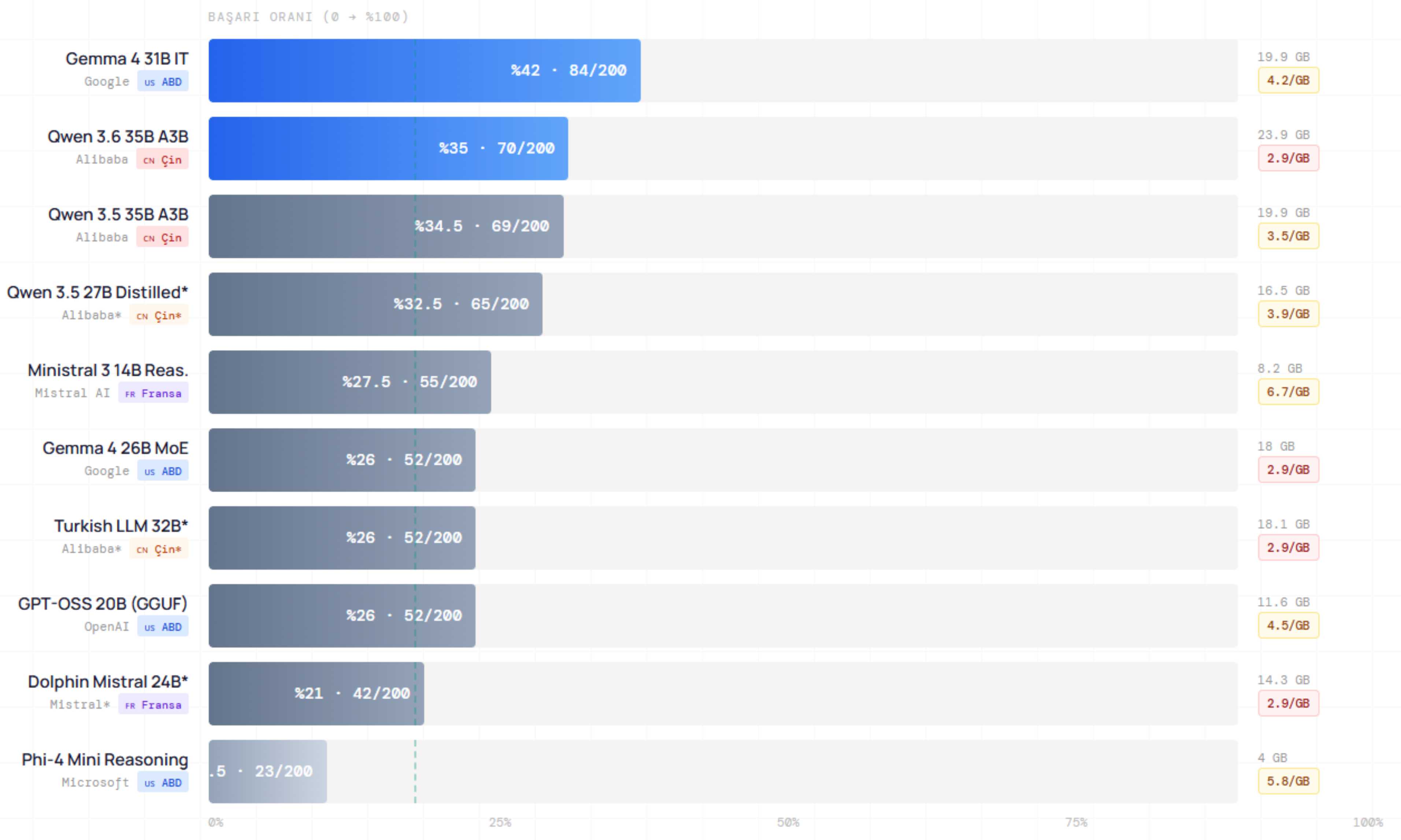
Yerel ortamda HCBfT-TR200 ile test ettiğimiz açık ağırlıklı 10 modelin yüzdelik başarı oranı. * işaretli modeller, bir temel modelin üçüncü taraflarca yapılmış ince ayarlı varyantıdır. Kuantizasyon: GGUF, Q4_K_M (8GB altındaki modeller için Q8)
Modellerin performansını insanlarla karşılaştırabilmek için 24 öğrenci ile HCBfT-TR200'ü testinden 1.200 yanıt gözlemi yaptık. "Genel eğitimli yetişkinler" bu bağlamda testi ortalama %37,9 başarıyla tamamladı. Güven aralıklarını da dikkate aldığımızda bu oran, test edilen 20 modelin çoğunun insan performansının altında kaldığını veya kayda değer miktarda onu aşamadığını gösteriyor. Test ettiğimiz API modelleri arasında yalnızca dördü (Gemini 3 Flash, Mistral Large 3, DeepSeek V3.2 ve Kimi K2.5), yerel modeller arasında ise yalnızca Gemma 4 31B IT bu insan eşiğini net olarak aşmayı başardı.
HCBfT Yol Haritası
HCBfT, yeni YZ sistemlerinin Türkiye'deki kurumlarda güvenli, güvenilir, etkin ve verimli bir şekilde konumlandırılabilmesi için standart bir metrik sunuyor. Bir ilk adım niteliğindeki TR200 veri kümesini, önümüzdeki dönemde 6 eksende geliştirmeyi planlıyoruz.
- Açık Uçlu Üretimsel Testler: Modellerin uzun soluklu akıl yürütmeye dayanarak içerik/medya oluşturma kapasitelerini ölçmek üzere, tamamı Türkçe değerlendirilecek doktora seviyesinde açık uçlu soruları da yapıya entegre edeceğiz.
- Çok Modlu (Multimodal) Sorular: Türkiye'nin özgün görsel ve işitsel kültürüne dayanan yeni bir değerlendirme katmanı oluşturacağız. Böylece modellerin sadece metni değil, bize özgü kültürel görselleri ve sesleri nasıl yorumladığını da göreceğiz. Bunun yanı sıra Türkiye'nin kentsel ve kırsal coğrafyasına dayanan harita temelli görevlerle mekânsal akıl yürütme ve coğrafi okuryazarlık da bu kapsamda ölçülecek.
- Akıl Yürütme İzlerinin Analizi: Büyük dil modellerinin arka planda ürettiği akıl yürütme izlerini (gizli düşünme fişlerini) insanlarınkiyle karşılaştırarak, anlamsal çöküşlerin mekanizmasını derinlemesine analiz edeceğiz. Yayın öncesi makalede bu bağlamda iki bulguya dikkat çekmekle yetindik: “Sezgisel kaçınma” (örneğin Türkiye’deki sınavlarda bu tür tuzak soruların yer aldığını bilen modelin hatalı olarak yanlış şıkka sapması) ve "boşlukları uydurarak doldurma (confabulation)." Örneğin bir modelin "yelken göğüs" terimini bilinen tıbbi tanımı yerine kendi hipotezine uyacak biçimde yeniden tanımlayarak doğru klinik akıl yürütme zincirini terk etmesi ve yanlış bir teşhise sapması…
- Veri Kümesinin Genişletilmesi: Mevcut veri kümesinde daha az soruyla temsil edilen "Kültürel Yetkinlik" gibi alt alanların hacmini büyüterek istatistiksel farklılaşmayı daha hassas bir şekilde ölçeceğiz. Ayrıca “anlama” ve “akıl yürütme” odaklı mevcut görevleri çeşitlendirerek “talimatlara uyma” ve “kültürel bağlama uygun kimlik (persona) benimseme” gibi yeni görev kategorileri ekleyeceğiz.
- Ezberleme Miktarının Ölçülmesi: Mevcut veri kümesinde yer alan "Ezber Bozma Tuzakları" paradigmasını sistematik bir tanı aracına dönüştüreceğiz. Böylece bir modelin doğru yanıtlarının ne kadarının aktif akıl yürütmeden, ne kadarının eğitim verisindeki soruları ezberlemesinden kaynaklandığını tahmin etmek mümkün olacak.
- İnsan Bazı: Çalışmamızın odağında yüksek maliyetli ve devasa boyutlu öncü (state-of-the-art) modeller yer almasa bile, kıyaslama yapabilmek adına Claude Opus 4.7 ve GPT 5.4 gibi, birçok ‘benchmark’ta zirvede olan sistemleri de değerlendirdik. Sonuçlar, trilyonlarca parametrelik bu en pahalı modellerin dahi HCBfT-TR200 testinde %80 başarı sınırının altında kaldığını gösteriyor. Peki “alanın uzmanı” bir insan aynı testte kaç puan alabilir? Bu bilgiyi de HCBfT’nin bir sonraki sürümünde paylaşmayı planlıyoruz.
Nihai amacımız; Türkiye'nin kamu, özel sektör ve akademik kurumlarında kullanılması değerlendirilen YZ sistemlerinin Türkçe özelinde gerçekten yetkin ve kültürel olarak uyumlu olmasını sağlayacak, sürekli güncellenen bir ölçüm standardı yaratmak. Türkçe gibi dijital kaynaklar açısından kısıtlı ve dünyada geliştirilen modellerde yeterince temsil edilmeyen diğer dillerle kapsamı uzun vâdede daha da genişletmeyi değerlendiriyoruz.
Modellerin test sorularını eğitim sürecinde ezberleyerek (benchmaxing) yanıltıcı skorlar üretmesini engellemek adına HCBfT-TR200 veri kümesini herkese açık olarak paylaşmıyoruz. Bununla birlikte tüm veriler, talep eden akademisyenlerin bilimsel doğrulamasına ve her tür katkısına açık. Farklı disiplinlerde uzman olan akademisyenlerden şimdiden HCBfT-TR200 hakkında geribildirimler almaya başladık. Ayrıca, kamu ve özel sektörden ekipler kendi geliştirdikleri dil modellerini veya Türkçe için ince ayar yaptıkları varyantlarını bize iletebilir, biz de bu modelleri test ederek sonuçları güncel tablomuza ekleyebiliriz.
İletişim: Emre Kızılkaya